NIFDAA is a forensic software which focuses on analyzing TCP/IP headers and Email logs to detect intrusions and suspicious activities in a machine. It is written in Java programming language and uses pcap4J for live packet capture / offline reading and RapidMiner machine learning operators for it’s detection purposes.
Scope
- Capturing/Reading Network traffic and logging TCP/IP packet headers
- Preprocessing Email logs and calculating word count statistics
- Performing classification on network logs
- Performing outlier detection on email content statistics
- Generating alerts based on outputs of above processes
- Cross platform Mobile Client for alert display using QT framework and C++
Research
- Applying Machine Learning Concepts in IDS development
- Correlating various system log anomalies to make critical predictions
- Security Attacks conducted on TCP/IP protocol stack
- Concurrent Batch processing
Functionality of Modules
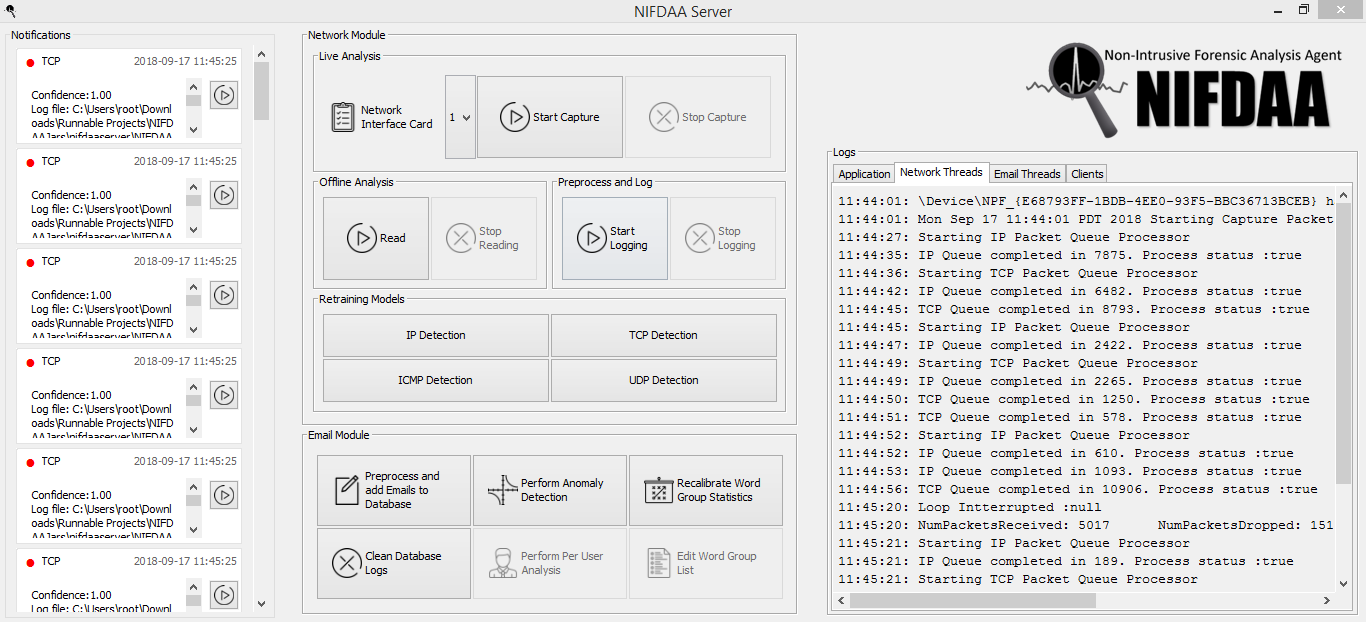
Network Module
Network Analysis
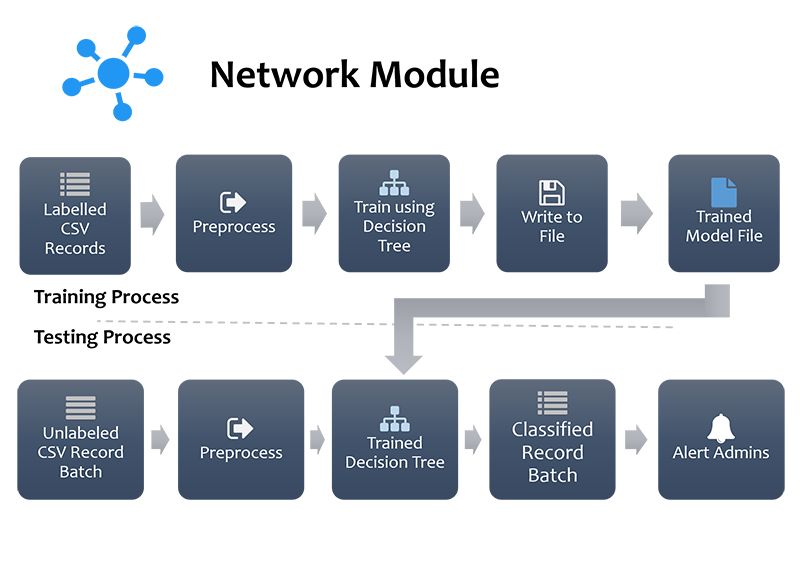
Network Analysis Module will be capable of capturing live traffic, allowing the application to analyze traffic from multiple sources if it were to be connected to a spanning port of a router/switch. It will focus on logging IPv4 and respective transport layer traffic for practical development purposes. It will also be capable of reading network packets from binary packet capture files. Once packets are read and preprocessed, they will be sent through the detection process containing machine learning classification operators. The output will be filtered traffic containing information of anomalous packets user defined in the training period.
Preprocessing and logging module
This module is capable of reading network traffic from binary packet capture files and logging them into the predefined format used by the application. It will store the preprocessed data into a batch of CSV files. . In the interest of being non-intrusive, only the network packet headers will be considered.
Network Training Module
This module will be capable of training the detection process used in the analysis module. User will be expected to label the CSV logs generated by the preprocessing and logging module; outside of the application according to his/her network analysis requirements. These labeled CSV files will be input into the training module and a trained model will be written to the application repository, to be used by the analysis process in future.
Email Module
Preprocessing and logging
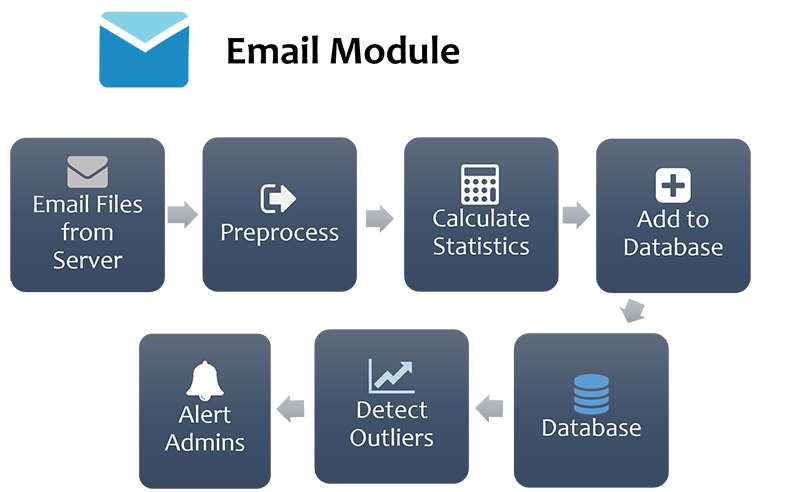
The application assumes that server logs are contained/obtained in a repository which contains the emails as text files, it reads through the text files, extracts email header information and logs them to the database. In the interest of being non-intrusive, only the word count statistics of email messages will be considered. Along with these logs, the application will calculate counts statistics of user defined word groups, the higher counts of which would represent suspicious or criminal activities administrators wish to be notified about. These word group statistics will also be recorded in the database. Administrators will also have an option to recalculate the word counts after alterations in the original parameters stored in the database.
Outlier detection
The records are retrieved from database in batches, each of which is run through an outlier detection process to detect unusual values which deviates from the usual patterns. This outlier factor is retrieved and records with benign outlier factors (not outliers) are removed, the rest is split into low, medium and high priority alerts which are then delivered to administrators with metadata information on the counts that caused them.
Alerts
Alert production module will consist of live desktop alerts and Email alerts sent to administrators that represent the outputs of above the aforementioned modules. Email alerts will have the option of being disabled. Each alert will display the properties that caused it and display the confidence machine learning algorithm has on its prediction. They will be classified to depict severity based on these confidence measurements.
User Customization
Apart from the above modules, user customization of the application’s internal logic will be automatically supported for users familiar with RapidMiner. Given that input parameters and output parameters have not been tampered with, these users will be able to edit the default RapidMiner processes provided at application distribution. They will be free to experiment and choose the process that serves their best interests.
Improvements
There are many future avenues which can be pursued to optimize this project.
- Production of a dataset capable of deriving user correlation (Network and Email) attributes
- Optimization of used machine learning models through realistic datasets
- Web-based wrapper for log inspection using J2EE and Bootstrap framework to support reinforced learning
- Developing Access control features
- Providing encryption for logs and UDP alert communication
- Tolerance Threshold Testing for different Hardware (Thread Usage, Network Traffic Load)
An important missing feature of the application is trained models. However, to train such models, the availability of a suitable dataset remains a major obstacle. Any such activity would require the above first or second points to be fulfilled.
In regards to module development, Network module has to be more inclusive of common protocols. It should support TCP stream reassembly for better feature extraction, rather than simple packet headers. In that interest, another windowing approach for periodical statistical anomaly detection of batches of packets is required. If such detection attributes were protocol agnostic, then information from different protocols can be used for correlation purposes. Email module could be implemented to obtain emails from the server itself. While the feature extraction uses a simple Bag-of-words approach, more sophisticated text similarity detection approaches can be utilized to aid in forensic investigations.
Conclusion
The objective that lead to development of this application were 1) to explore machine learning concept usage in practical applications, and 2) exploring Correlation Possibilities. While the first objective was achieved, the lack of suitable dataset restricted further improvement of the project.
The optimization of detection “models” were also limited due to the shortcomings of available datasets and resource constraints. But the application presents a general framework on how to capture and analyze live network traffic for anomaly detection.